Project 4 Concurrency Control
本文是接着这位博主的文章丯是幡动,他写了 lab0 ~ lab3 的详细攻略,可惜断更了。为了致敬先人,我文章标题都是和他同一个格式的。🤣
这个lab主要是实现一个Multi Verson Concurrecy Control,一般来说会用一个table专门保存历史值,但为了简化,Bustub把历史值保存在transaction里。
Isolation level 在基础task要求达到SNAPSHOT ISOLATION, 而在bonus task部分提升到 SERIALIZABLE。
Task 1: Timestamps
1.1 Timestamp Allocation
Read timestamp 在transaction创建时分配,因为后续需要用read timestamp来确定自己读取数据时候的权限。
Commit timestamp在transaction执行完毕准备commit的时候分配,标记一下commit的时间。
因此在TransactionManager::Begin()中:
1 | txn_ref->read_ts_ = last_commit_ts_.load(); |
在TransactionManager::Commit()中:
1 | last_commit_ts_.fetch_add(1); |
1.2 Watermark
Watermark 这个类记录了在所有正在运行中的transaction的read timestamp以及计数。主要结构是一个哈希表,key是read timestamp,值是这个timestamp的计数。同时,watermark_标注着所有时间戳中最小值。后续垃圾回收需要使用。
这个实现很简单,关键点就是remove的时候,如果remove掉最小时间戳,就需要遍历一遍哈希表寻找剩下时间戳的最小值。这个过程需要从$O(n)$至少优化到$O(lgn)$,最多可以到$O(1)$。
优化到$O(lgn)$可以使用priority queue或者红黑树之类的,insert时$O(lgn)$,remove时$O(lgn)$。
Watermark新增:
1 | class Watermark { |
AddTxn():
1 | auto Watermark::AddTxn(timestamp_t read_ts) -> void { |
RemoveTxn():
1 | auto Watermark::RemoveTxn(timestamp_t read_ts) -> void { |
Helper method:
1 | } |
到这里就可以通过测试 txn_timestamp_test
Task #2 - Storage Format and Sequential Scan
在Bustub中,transaction的数据会被存储到三个地方,table heap, transaction manager, 和transaction内部。
Table heap一直存储的是最新的数据,这也和未实现MVCC之前的普通版数据库保持了一致。
transaction manager 中
这个实现类似于课上讲的delta table storage model,但并不会专门维护一个储存delta table,而是将过去版本的delta直接存在各个transaction的内存中(即class transaction中的std::vector

忘记table heap结构的再回忆里一下:
2.1 Tuple Reconstruction
原理介绍
在execution_common.cpp里完成ReconstructTuple函数。MVCC会为每一个tuple维护一个”历史记录“,记录这个tuple从诞生到逐渐变化到最新值的一系列中间步骤,类似于git里保存着commit的历史记录。而当需要查找过去的某一个历史数值的时候,就需要利用最新的tuple去重新构造历史数据,而这个函数就起这样一个功能。
如图,这个函数需要根据输入的base tuple(即最新的tuple),去遍历undo log链表,最终得到想要的历史tuple。
undo log具体结构与作用下图一目了然:

具体实现
ReconstructTuple:
1 | namespace tuple_reconstruction_helper { |
要注意的是undo_logs里tuple的schema并不是参数schema,而要根据undo_logs.modified构建。比如schema是$[integer, double, boolean]$,某一个undo_logs的modified是$[false, true, true]$,那么undo_logs里tuple的schema就是$[double, boolean]$.
此时可以通过测试TupleReconstructTest
2.2 Sequential Scan / Tuple Retrieval
这个task需要重写project 3里的sequential scan executor ,使其支持通过read timestamp来读取历史数据。
原理介绍
sequential scan executor需要扫描table scan,根据read timestamp获得undo logs,再重构tuple并返回重构后过去的tuple。
这个MVCC sequential scan executor有三种情况:
table heap的tuple是最新的。
判断方法: transaction 的 read timestamp 等于 table heap里tuple的timestamp。
处理: 直接返回tuple。table heap的tuple被当前transaction修改过
判断方法:transaction_id 等于 tuple timestamp
处理:直接返回tupletable heap的tuple被uncommit的其他transaction修改过 或 tuple的timestamp比transaction的read timestamp新
判断方法:排除1、2都是
处理:利用之前实现的ReconstructTuple回溯寻找历史tuple
额外解释一下第二种情况,在Bustub里,每个transaction有个用uint64_t表示的id,每个timestamp也用64位无符号整型表示。并且timestamp和transaction id的数值范围是没有重合的:
1 | [ timestamp ][ transaction id ] |
可见timestamp从0开始直到TXN_START_ID - 1,tranaction id从TXN_START_ID开始。所以正常来说一个timestamp的数值是肯定比任何一个transaction id的数值要小。当一个正常的tuple被一个还没有commited的transaction修改的时候,tuple的timestamp会临时改成这个transcation的id值。所以如果你发现有一个tuple的timestamp特别大,大于timestamp大小的上限,那么这一定是被未commited transcation修改过,并且timestamp的数值就是这个修改它的transaction id值。
而transaction id都特别大,为了方便人类直观地看transaction id,Bustub可以输出一个从TXN_START_ID开始计数的从零开始的较小的human readable transaction id.
而我的sequential scan修改前:
1 | void SeqScanExecutor::Init() { |
判断tuple是否删除、filter_predicate之类的判断保留,只需要增加if里的内容就行。
但要注意的是,对于没有MVCC的scan,如果一个table_heap里的tuple被删除了(is_delete = true),那么直接跳过就行,但是对于MVCC的scan,如果一个tuple被删除了(is_delete = true),仍然有可能返回内容,因为此时的tuple被删除,但有可能在transaction的timestamp read时期还没有被删除,所以需要查询undo_log来看这个tuple过去的内容。因此要删除上面if里的 *!meta.is_deleted_ &&。我刚写的时候直接删除了if里的!meta.is_deleted_ &&*,结果在测试中出错了,后来才意识到,要在后续case1&2中再检测 *!meta.is_deleted_ &&*,如果delete,则跳过该tuple。
具体实现
SeqScanExecutor::Next 重构后:
1 | auto SeqScanExecutor::Next(Tuple *tuple, RID *rid) -> bool { |
我的SeqScanExecutor::Init() 也有点修改,就不放出来了,可以根据Next推测出我增加的class成员。
对应的txn_scan_test有点特殊,这个test并没有帮你写全,你需要自行补齐测试txn2~txn5的语句以及期望结果。而可以通过实现execution_common.cpp里的TxnMgrDbg 函数来辅助找到期望结果。
TxnMgrDbg 就是输入一个table_heap,其打印出该table里所有tuple的**当前值、所有回滚日志值(undo log)*,这样便于直观看一个table heap的情况。虽然不是必须实现的,但这里强烈建议实现一下,因为后续有大量测试有可以利用这个函数方便debug。这个函数的实现可以参考的ReconstructTuple(),函数内注释也给出了参考格式,用一个std::stringstream*一段段构建字符串就行了,这里就不放出来我的实现了。
根据TxnMgrDbg即可推测出隐藏测试的期望结果,补齐测试后即可通过txn_scan_test.cpp的第二个测试ScanTest。
隐藏测试提示:
txn和标号和其txn_id并不一致,总结如下:
txn0: txn_id = 0,
txn1 txn_id = 2
txn2: txn_id = 4 read_ts=2
txn3: txn_id = 6 read_ts=3
txn4: txn_id = 8 read_ts=4
txn5: txn_id = 10 read_ts=5在TxnMgrDbg中。txn_id 从初始值4611686018427387904开始递增,可以利用
1
txn_id ^ TXN_START_ID
将一个原始的txn_id 转化成便于人类阅读的id。(本质和我上文讲的从TXN_START_ID开始计数一样)例如:
1
2txn_id = 4611686018427387904; // txn_id初始值
txn_id ^ TXN_START_ID = 01
2txn_id = 4611686018427387905; // txn_id初始值+1
txn_id ^ TXN_START_ID = 11
2txn_id = 4611686018427387906; // txn_id初始值+2
txn_id ^ TXN_START_ID = 2
Task #3 - MVCC Executors
这个任务我们将重构executors,从这里开始,你的bustub将不与project 3的测试兼容。所以如果想要继续做project 3的leaderboard优化部分,一定记得commit并开一个新分支。project 3优化攻略
3.1 Insert Executor
你需要正确设置插入tuple的metadata。timestamp需要按我之前说的,设置成临时时间戳,也就是执行插入的transaction的id值,因为这表示tuple被尚未commit的transaction修改过。同时,需要把插入的RID添加到write set里。
插入过程如下图:
可见新tuple的ts=1009,这是一个很大的数值,表示临时时间戳,看个位数可知执行插入的是id=9的transaction。 同时还要更新TxnMgr里的内容。注意,图上的是插入的情况,也就是插入的tuple没有任何历史值,更普遍的情况是更新一个拥有历史值的tuple,比如更新tuple (C, 4, ts=4),当然,这些不是insert executor需要关心的。
历史记录用一个单向链表连接,Undolink是连接的链子,Undolog是内容,VersionUndoLink是一个由transaciton Manager维护的特殊的Undolink,是链表的第一个链子。学过数据结构的就会知道,这是一个带sentinel的链表哦。

Bustub提供了UpdateTupleInPlace and UpdateUndoLink / UpdateVersionLink 这俩函数来分别更新table heap 和 version link(即不能用project 3时候的InsertTuple函数来插入新值了)。不过,目前不用管这俩函数。
在insert_executor中添加:
1 | std::optional<RID> insert_rid_optional = table_info_->table_->InsertTuple( |
3.2 Commit
原理介绍
目前Commit函数只能同时处理一个transaction,因为需要用transcation_manager里的commit_mutex_来保护commit。本部分需要拓展commit函数功能,步骤如下:
获取commit_mutex_
获取新的commit timestamp(但不要增加last_committed_ts值,这会导致last_committed_ts在commit完成前处于不稳定状态。)
遍历所有此transaction修改过的tuple(利用write_set,这也是为什么上部分需要加入write_set),更新tuple的时间戳为commit timestamp。(这些tuple包括所有执行器修改过的:insert, update, delete)
将transcation状态设为committed,并且更新transcation的commit timestamp。
更新 last_committed_ts
效果如图:
注意:原本的直接增加last_commit_ts_需要删除!删除部分如下:
1 | last_commit_ts_.fetch_add(1); |
具体实现
1 | auto TransactionManager::Commit(Transaction *txn) -> bool { |
之后就可以在bustub-shell中运行提供测试的一系列指令了。你会看到,当transcation还没有commit 的时候,select * from t1; 只会打印三行数据;当transcation commit之后,可以打印出transcation加入的第四行数据。
3.3 Update and Delete Executor
之前只实现了不需要更新UndoLink的insert,现在要开始实现update和delete。Update和delete实现很类似,update加入一个新tuple,delete也加入一个新tuple(只不过is_delete=true),可以将它们的公共部分放在execution_common.cpp。
如果一个tuple被一个uncommited transaction修改了,那么它在commit前不能再被其他transaction修改,否则会覆盖之前修改的值,也就是write-write conflict。如果后来的transaction试图修改tuple,那么就会产生write-write conflict,进而abort。此时需要将transcation state设为TAINTED,并且抛出一个ExecutionException。
注意,一般来说project 3对update executor的实现都是pipeline,也就是每次被调用Next(),调用一次child_executor_->Next(tuple, rid)获得一个tuple。但此时需要把update变成pipline breaker,也就是在init()中一次性获取所有child_executor_->Next(tuple, rid),储存在成员变量中。调用next()的时候在从自己储存的tuples中获取。这样可以防止在扫描过程中child_executor中剩余tuple被其他transaction修改。
图示简介
Delete过程示意图:
对于Delete,需要先生成一个包含原tuple所有数据的undoLog插入该transaction中,然后原tuple更新成.is_delete=true。图中其实就一个单向链表插入节点。
Update同理:
只不过undoLog中只需要保存被修改的column。
有一种特殊情况就是同一个transcation不断修改tuple,此时不会产生ww-conflict,可以直接修改最新值,不过如果修改了新的tuple,要更新其undoLog:

如图,Tnx9可以多次更新col2,但其继续更新col1时,要记得往undolog中增加col1的旧值。

当先插入一个tuple,未commit,再修改或者删除的时候,不需要生成一个undo log,因为并没有历史值,如上图。 并且commit的时候将ts设置为0(一般来说应该设置为commit timestamp),因为以前这里没有tuple,现在txn9插入一个tuple紧接着又删除了,仍然没有tuple,所以ts设置成0可以让任何遍历到这里的transaction都得知这里没有tuple(tuple被删除了)。
主要思路
Update executor 执行步骤:
- 先判断是否出现WW-Conflict。如果元组的时间戳大于事务读取时间戳 且 不等于事务时间戳, 则说明已被其他事务修改过,发生了一个写写冲突。 需要将事务标记为 Tainted, 然后抛出一个异常。
- 进入更新逻辑,更新数据 + 更新undo log。
- 判断是否被当前事务修改过。根据元组的时间戳和当前事务时间戳判断。
- 若是, 则需要合并新旧undo_log, 并使用合并后的 undo_log 更新原undo_log。(如果此时没有旧undo_log,说明是当前事务插入的元组,不需要合并与更新如图)
- 若否, 则直接新建一个 undo_log, 并更新 version_link。
WW-conflict 有两种情况:1.被一个未commit的其他transaction修改;2.被一个晚于当前transaction且已commit的transaction修改过。这两种情况都可以用 tuple.ts > transaction.read_ts 表示,第一种情况tuple.ts是一个很大的不稳定态的数,第二种情况是一个比当前事务read_ts大一点的稳定态的数。但注意打个补丁:tuple.ts是一个很大的不稳定态的数的时候,排除是当前transaction修改后得到的不稳定态就行。
比如:
tuple.ts = 100008, txn.read_ts = 9 属于第一种情况,被一个uncommit的事务修改过。
tuple.ts = 10, txn.read_ts = 9 属于第二种情况,被一个更新的commited事务修改过。
tuple.ts = 100009, txn.read_ts = 9 属于补丁情况,被txn9自己修改过。
此处就可以用到先前提及的**UpdateTupleInPlace()**来原地更新tuple,利用checker来判断是否出现ww-conflict。
除了跟原来一样更新数据,MVCC部分还要再更新undo log,具体过程上面步骤也讲了。
要记得,tuple更新成功后需要跟insert executor一样手动加入transaction的writeset。
部分实现
UpdateExecutor.cpp:
Init():
1 | void UpdateExecutor::Init() { |
Next():
1 | auto UpdateExecutor::Next(Tuple *tuple, RID *rid) -> bool { |
除此之外,我还在execution_common.cpp中实现了两个helper method。
1 | auto CreateUndoLog(const TupleMeta &tuple_meta, const Schema *schema, const Tuple &old_tuple, const Tuple &new_tuple) |
CreateUndoLog(): 通过update前原始元组和其信息(old_tuple, tuple_meta, schema) 以及更新后的元组**(new_tuple)** 生成他们对应的 undo_log。
1 | /** Merge two undo_logs, and return the merged undo_log. */ |
MergeUndoLog(): 当update一个已经被update过的元组,用此函数合并新旧undolog,返回合并后的undolog。注意:合并时旧的undolog具有更高优先级。
还需要一个设置transaction 状态为Tainted的函数:
1 | void TransactionManager::SetTxnTainted(Transaction *txn) { |
一定要通过TransactionManager中的函数来调用txn->SetTainted()而不能直接使用,因为需要锁上txn_map_mutex_ 后才能更新transaction状态。
我还在execution_common.cpp里实现了两个辅助函数:
1 | auto GetUndoLogSchema(const UndoLog &undo_log, const Schema *schema) -> Schema; |
生成undolog中tuple的schema。
1 | auto IsWriteWriteConflict(Transaction *txn, const TupleMeta &old_meta) ->bool; |
用于判断是否出现Write-Write Conflict。
除此之外还有一些helper method可以自行定义,这些实现就不放出来了,通过update_executor代码以及前面讲的思路可以自行推断。
而Delete executor 实现一摸一样,就不赘述了。
此时即可通过txn_executor_test中除了GarbageCollection和GarbageCollectionWithTainted之外的其余8个测试。
3.4 Stop-the-world Garbage Collection
在原本的实现中,我们只会生成transaction并加入transaction map后,而从来不会从transaction map中删除transaction,即使这个transaction已经commit了。因为我们的undologs是直接储存在transaction结构中,为了让后续事件可以回溯tuple的历史值,所以我们不能删除transaction。
原理介绍
但是仔细想想,如果一个transaction没有任何undolog,那么它可以直接被删去。同时,只有未commited的事务才有可能继续去读历史值。而所有uncommited事件中的最小的read_ts决定着undolog链表读取的“最深深度”。
即如下图,所有未commit的事务的最小的read_ts=3,即这些事务最深回溯读取到第一个小于ts=3的undolog;换句话说,ts为0、1、2的undolog再也不会被读到。(后半句话定性理解,因为严格来说是 “第一个小于等于ts=3的undolog”之前的再也不会被读到,见下面例子。 )
如:tuple A,第一个ts小于3的undolog是 **[ _, 3, ts=3 ],由于未commited的事务的最小read_ts=3,所以[ _, 2, ts=2 ]和[ _, 1, ts=1 ]**已经不可能再被读到;
同理,tuple C, 第一个小于3的undolog是 **[ _, 2, ts=2 ],而后面的[ _, 1, ts=1 ]**不可能再被读到了。
而对于第四行,base tuple [ D, 3, ts=3 ] 就是 “第一个小于等于ts=3的undolog”, 所以第四行之需要保留base tuple就行。图中并没有其余undolog,但第四行有undolog,也都不可能被读到。

而在 “第一个小于等于ts=3的undolog” 之后的所有undolog都永远不可能再被读到了,所以可以标记为”无用”。如果一个transaction中所有的undolog都是”无用“的,那么就可以删除这个transaction释放空间。(如上图中的 Txn 1)
注意,虽然最小的read_ts=3,但某些tuple可能没有一个ts正好等于3的undolog,所以我们需要保留的是回溯中遇到的第一个 “第一个小于或等于 ts=3” 的undolog,如图中的第三行 tuple C。
而未commit的transaction的最小read_ts 可以通过我们Task1所实现的watermark获得。
实现思路
最开始,我的思路是:为了提高GarbageColletion() 的效率,我打算在Commit()中对无用的undoLog进行一定的预处理,即提前标记一下,这样后续垃圾回收可以更方便。但写了一半发现,这样并没有能提高垃圾回收效率,反而让Commit()函数很臃肿。原本事务commit很快,要预处理垃圾则会变得很低效,这样整个数据库的效率都变低了。就如同为了加快垃圾处理速度,所以把一个大的垃圾箱换成小的,结果垃圾箱满了,垃圾被丢的到处都是;垃圾箱处理是高效了,但满大街捡垃圾反而低效了。而工作量大的GarbageColletion()可以在数据库不繁忙的时候调用,同时可以使事务commit更轻量,响应速度更快。所以还是大的垃圾箱好用啊。
后续思路就是,
- Commit()中记录事务拥有的Undolog数量。(TransactionManager中加一个hashmap来记录事务号与其对应的undolog数量)
- 直接在GarbageColletion() 中遍历PageVersionInfo,对于每一个versionUndoLink链表遍历,记录各事务可以删除的Undolog数目。
- 遍历Committed transaction,如果一个事务可以删除的undolog数目等于其拥有的undolog数量,删除。
Tips:
很重要一点是这个链表其实要从base Tuple开始遍历(即tuple的最新值),这样找到的 “第一个小于等于watermark的undolog” 才是正确的,因为base tuple也可能是这个 “Undolog”。而上述遍历PageVersionInfo操作不能查到base tuple的ts,所以我在VersionUndolog 中增加一个新成员变量来记录base tuple的时间戳,Commit() 的时候更新。后续垃圾回收时即可通过VersionUndolog 查看base tuple的时间戳。
删除undolog之后记得要处理遗留下来的“空悬” undolink。为了高效其实不一定需要删除undolink,记得避免空悬undolink带来错误就可以。
实现代码
GarbageCollection():
1 | void TransactionManager::GarbageCollection() { |
在VersionUndoLink 中添加
1 | /** The base tuple(newest) timestamp. */ |
而在 Commit() 中添加:
1 | timestamp_t commit_ts = last_commit_ts_.load() + 1; |
至此可以通过 txn_executor_test.cpp 中全部10个测试。
Task #4 - Primary Key Index
Bustub 支持 primary key index (主键索引),使用方法如下:
1 | CREATE TABLE t1(v1 int PRIMARY KEY); |
可以在建表的时候设置主键,Bustub会自动建立索引并将 is_primary_key 设为 true。主键只能唯一并且键值不能重复。
注意,在测试中全部假设:如果有primary key,那么不会再创建其他index。 不过你仍然可以无视此条,考虑拥有其他index情况。
4.0 Index Scan
可跳过,等到4.2再实现。
实现也很简单,直接复制Seqscan即可。
4.1 Inserts
需要修改 insert_executor来支持primary_key 。
Insert Executor步骤:
- 检查tuple是否已经存在,如果存在,则abort。
- 仅限于Task4.1, 后续Task 4.2 中会进一步修改此情况。
- 只需要将事务状态设置为Tainted,这表示此事务将要abort,但为清理数据;然后抛出ExecutionException 异常
- 将新元组插入table_heap,ts设为 transaction temporary timestam (跟之前一样)。
- 更新index。如果该tuple重复,则Index的插入操作会返回false (虽然步骤1检查过,但此期间别的事务也有可能更新index)。此时需要abort,这会导致步骤2插入的tuple没有被索引指向。

步骤3情况如图。当试图插入C时,先检测,发现没有重复,于是继续步骤2,然后到步骤3时,发现其他事务抢先一步更新了index插入了C,所以此时transaction abort,而其插入的 ”C, 4, ts=1009“ 没有被索引指向。
实现:
1 | auto InsertExecutor::Next(Tuple *tuple, RID *rid) -> bool { |
此时可以通过txn_index_concurrent_test的第一个测试IndexConcurrentInsertTest。
到了这里官方建议先跑一遍线上测试,线上有几个隐藏测试,确定能拿80分了,再继续下面任务。
4.2 Index Scan, Deletes and Updates
思路
接下来轮到delete 和 update executor。正如之前为seq_scan executor支持MVCC一样,先要修改成MVCC版本的index scan executor,然后再为删除和更新执行器提供index支持。这部分直接抄之前seq_scan_executor的实现即可。
当index中插入一个entry后,这个entry永远指向同一个tuple的RID,即使这个tuple被标记为deleted,也不能将这个entry从index中删除。这样,其他事务仍然可以回溯这个被标记为delete的tuple,读取其被删除之前的历史值。
同时,需要再次修改insert executor。当insert executor插入一个被delete executor删除的tuple时,只需要更新tuple而不需要重新插入index(因为index中并没有删除指向这个tuple的entry呢)。并且要记得检测 write-write conflict。

如上图,“B, 2” 已经被删除了,现在txn9试图重新insert一个 “B, 3” 。但是发现键 B 已经存在于index中,所以只需要更新这个被标记为deleted的tuple,不需要重新插入并加入index,就像update一样。
同时,当多个事务作用同一个tuple时,可能会出现race condition,需要将部分事务abort。VersionUndoLink中的in_progress可以用于表示“有一个事务正在占用此tuple“。其实就相当于一个tuple的锁。这篇博客讲了怎么用in_progress锁住tuple;同时也提醒我在commit时才能解锁。
还有,在某一段时间,tuple的值与其第一个undolog完全相同(第四行),需要让seq_scan_executor考虑到这种情况。
而这里有一个bug卡了我很久,一定要跟图中一样,先更新undolog再更新tuple!!!! 不然别的线程就可能无法在更新的过程中正确读取。并且update的时候一定要考虑是否能保持同时读取正确!
insert_executor步骤如下:

这部分真是四个lab中debug最艰难的,多线程还是要靠printf大法,gdb真用不来。
我debug了很久,多线程是太难debug了。建议可以先把测试中的线程数量从8改为1,测试单线程通过后再逐步增加线程数。还可以将 add_delete_insert 设置位false,来判断bug是否由delete引起。要注意GetVersionLink() 是获得versionlink的copy,所以不能直接 GetVersionLink()->in_progess = false 来释放锁。
还有,一个transaciton如果先成功执行一条sql更新tuple,再接着执行另一条sql但是abort了,这时候需要复原第一条sql改变的内容。保持数据库Atomicity。这一特点会在IndexConcurrentUpdateAbortTest 中测试,但这其实是Bonus Task 1中的内容。
实现
放最难的UpdateExecutor出来,InsertExecutor 和 DeleteExecutor差不多。我刚开始忽视了MVCC的一个特性 在写入过程中要始终保持Undolog可以正确读取 (代码中表示为,更新tuple的时候,先插入新Undolog,再更新tuple数据,仔细看讲义中的图) ,导致一堆bug,花了很久时间才后知后觉。
1 | void UpdateExecutor::Init() { |
关键的就是 while(true) 获取锁那里,先检查WW-conflict, 再尝试获取锁,不断循环直到成功获取锁。 获取后再检查一遍WW-conflict,以防在 拷贝TupleMeta ~ 成功获取锁 之间的时候tuple被修改。
获取锁之后,在commit的时候释放。因为即使修改完释放也完全没用,因为meta.ts也被修改成临时timestamp,别的transaction也获取不了。
如果transaction中途Abort,需要释放已经获取的锁,并且将已经成功修改的tuple复原,以保持Atomicity。Tuple 复原(Rollback)可见Bonus Task 1,我用的是方法一,方法二太复杂。而之所以要用复杂的方法二,而不是直接修改,则是因为我上一句提到的,MVCC读写同步进行,要始终保持读取的正确;直接修改会导致有一小段时间不能正确读取。
1 | void TransactionManager::Abort(Transaction *txn) { |
上锁与解锁,用一个变量in_progress表示锁需要让这个变量atomic test-and-change 。可以用std::atomic
1 | auto TransactionManager::LockTuple(RID rid) -> bool { |
之后可以通过txn_index_test(除了UpdatePrimaryKeyTest) 和 txn_index_cocurrent_test。也要注意之前的test仍可以通过。
4.3 Primary Key Updates
思路
4.2 我实现updateExecutor的时候默认 primary key不可被更新,而这个部分则是让primary key也可以被更新。
当试图更新primary key的时候,将update转化成先删除再插入。先删除所有将被更新的旧tuple,再插入所有新tuple,最后更新primary index(这里要先删除旧entry再插入新entry,因为entry指向的RID改变了)。
实现
先删除再插入的逻辑跟DeleteExecutor和InsertExecutor一模一样,可以先将其中的逻辑打包成函数放在executor_common.cpp,UpdateExecutor中直接调用即可,并且最后要记得更新primary_index。
先在UpdateExecutor::Init()中随便查看一个新tuple是否更新了primary_key。
1 | void UpdateExecutor::Init() { |
在UpdateExecutor::Next() 中先查看是否在更新primary_key。如果是,则进入primary_key更新的逻辑,一次性更新所有tuple;如果否,进入常规逻辑。
1 | auto UpdateExecutor::Next(Tuple *tuple, RID *rid) -> bool { |
至此,可以通过UpdatePrimaryKeyTest。不过注意gradescope上有隐藏测试。
Bonus Task
Bonus Task 1: Abort
这部分之前也提过,我用的是简单点的Implementation 1。分两种情况:有Undolog和没有Undolog。有Undolog代表之前修改过tuple,需要利用undolog rollback原本的tuple;没有undolog说明之前新插入了tuple,不用rollback,直接将TupleMeta.deleted设为true。
1 | void TransactionManager::Abort(Transaction *txn) { |
可通过AbortTest。有个疑问是,implementation 2要远远比1复杂,但我没看出2相比1有什么巨大优势,也就是可以提前释放一点内存。
Bonus Task #2 - Serializable Verification
目前的 Isolation Level
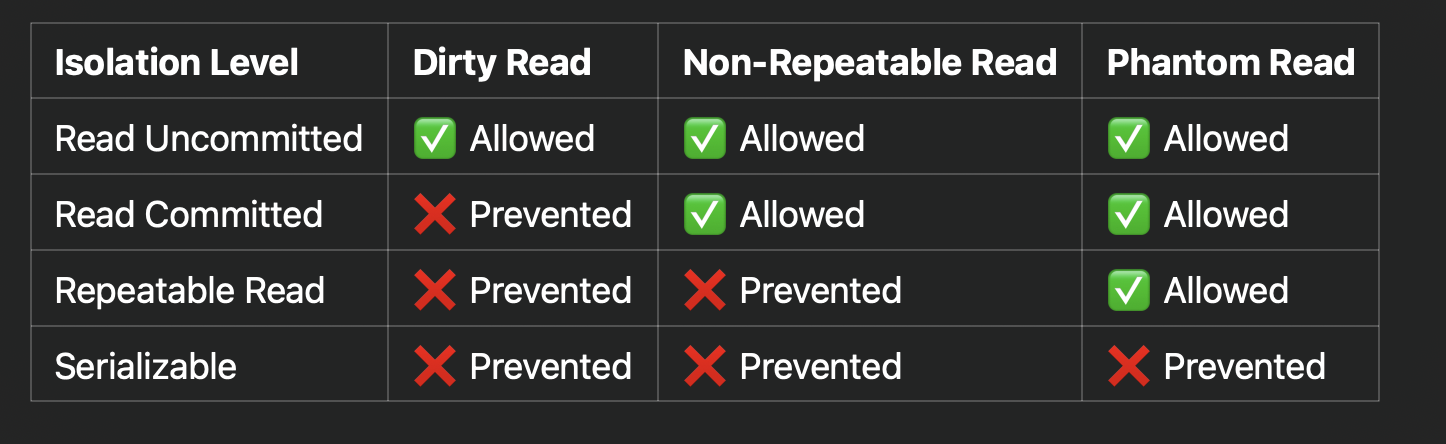
很多资料都会有上图,但其实有一定误导性,会让人反过来认为只要prevent Phantom Read,那就一定是Serializable。但即使杜绝了Phantom Read,仍然可能不是serializable的。也就是说,还有一层isolation level,即Snapshot Isolation。以上根据三种现象来确定隔离等级的是由ANSI SQL-92规定的,这也是为啥主流数据库把隔离等级
命名成这几个。如今看来不够精细。可参考A Critique of ANSI SQL Isolation Levels
隔离度关系如图:
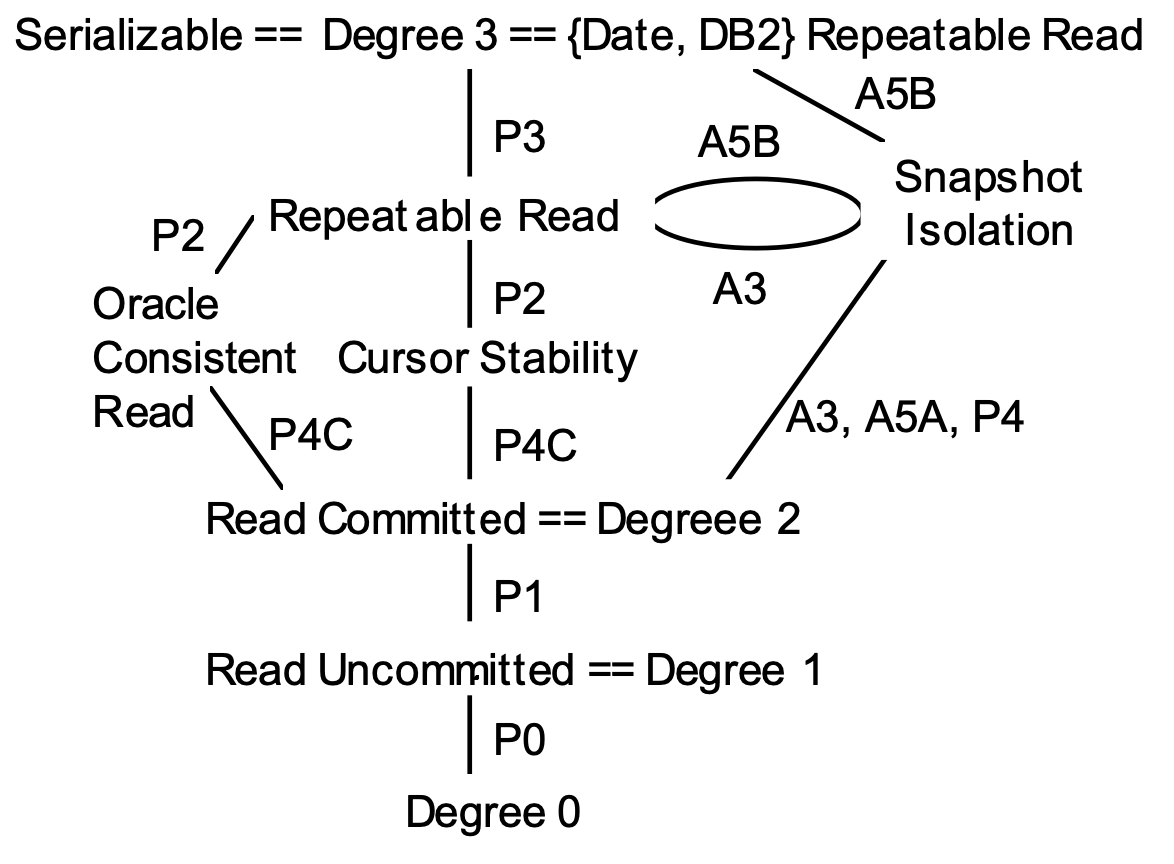
可见snapshot isolation 是和repeatable read差不多平级的一个隔离度。Snapshot isolation level虽然可以让事务不能读新插入的数据,来避免“常规”Phantom Read,但是这种无法看见新插入
数据的特点反而会让其产生重复操作而违反完整性约束!
📌 例子:工作时长约束
假设有一个任务管理系统,规则是:
- 所有任务的总时长不能超过 8 小时。
- 事务 T1 和 T2 都检查当前任务总时长,并尝试各自插入一个 1 小时的新任务。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
BEGIN;
SELECT SUM(duration) FROM tasks WHERE project_id = 1; -- 读取当前任务总时长(7 小时)
INSERT INTO tasks (project_id, duration) VALUES (1, 1);
-- 事务 T2
BEGIN;
SELECT SUM(duration) FROM tasks WHERE project_id = 1; -- 读取当前任务总时长(7 小时)
INSERT INTO tasks (project_id, duration) VALUES (1, 1);
-- 事务 T1 提交
COMMIT;
-- 事务 T2 提交
COMMIT;📌 问题
- T1 和 T2 都在 7 小时时读取了同样的快照,并认为可以再插入 1 小时的任务。
- 由于 快照可见性,T1 和 T2 彼此看不到对方的插入,它们都成功提交!
- 结果:任务总时长变成了 9 小时,违反了业务规则。
💡 这就是 SI 无法完全避免 P3 的地方——即使事务的快照里看不到幻影数据,它们仍然可能同时执行互相冲突的操作。
现在Bustub已经可以利用MVCC支持prevent Phantom Read,所以目前为止的Bustub就是Snapshot Isolation的。
用bustub-shell即可检测你的实现是否prevent Phantom Read: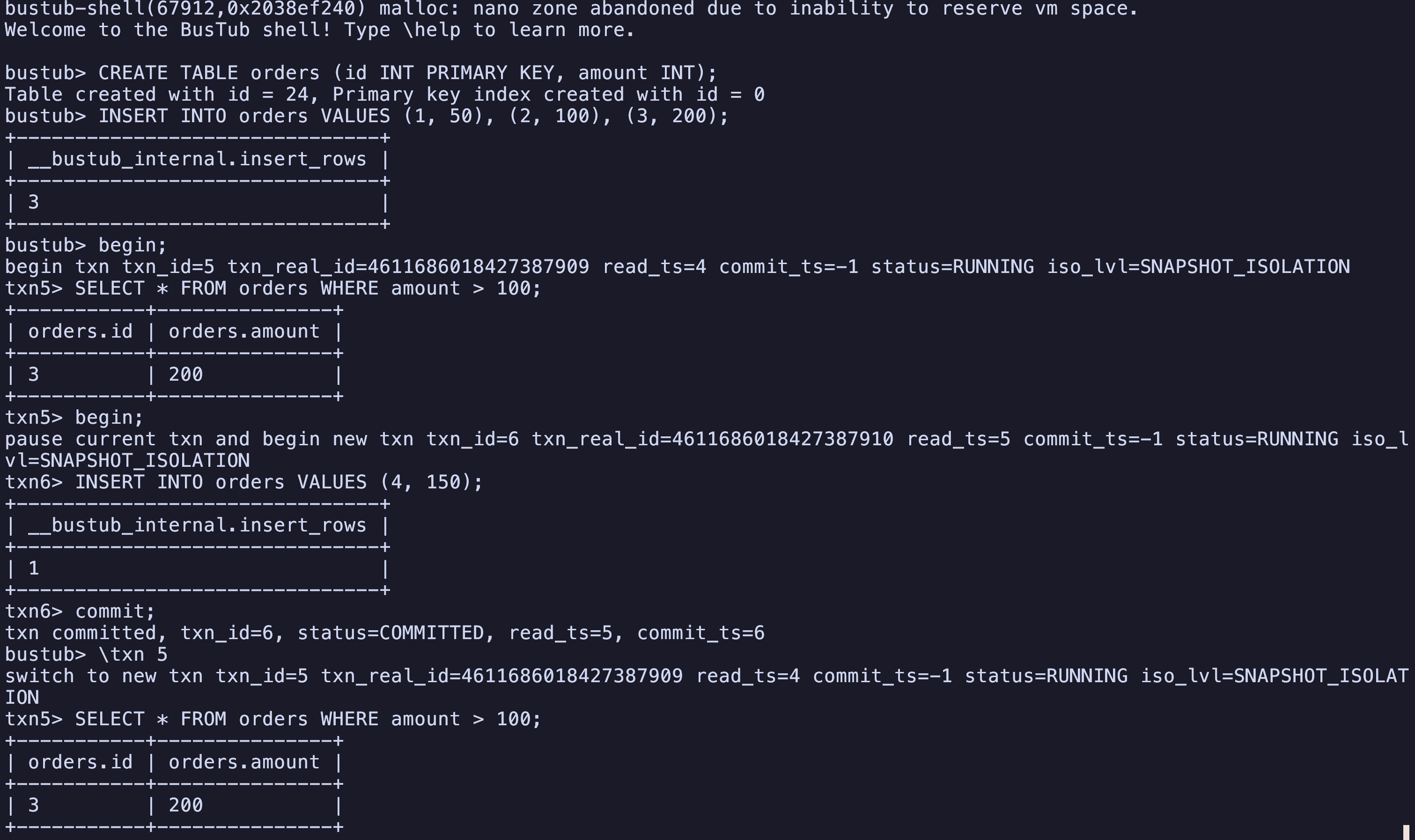
而这部分Task就是要让Bustub支持Serializable Isolation level。方法是通过一个Serializable检测器,当transaction commit 的时候检测是否满足serializable,如果不满足直接abort。这类似于PostgreSql实现serializable的方式。
Skew Write
对于一个表:
1 | maintable: |
先插入并commit:
1 | maintable: |
此时同时开启txn2和txn3,即它俩read_ts相同,面对的都是同一张表(如上)。txn2试图将所以a清零,txn3试图将所有a设为1。
txn2先执行
1 | UPDATE maintable SET a = 0 WHERE a = 1; |
将第1,2行的a修改,得:
1 | maintable (txn2's perspective): |
txn3再执行
1 | UPDATE maintable SET a = 1 WHERE a = 0; |
如果是serializable isolation,即transaction之间完全独立不受干扰,txn期望结果应该是基于原表的修改:
1 | maintable (txn3's expectation): |
但由于txn2提前修改,实际得到的结果是:
1 | maintable (txn3's perspective): |
Serialiable需要保证transactions运行独立,或者说不管实际执行顺序是怎么样,都要等价于“一个接着一个运行”。txn2将a全设为0,txn3将a全设为1;所以结果a全为0或者全为1都是满足serilizable的。而上图中一半0一半1的结果是违反serializable的。这也是我之前说的即使prevent Phantom Read也可能不是serializable的证据。而这种情况被称为write skew。Snapshot isolation无法避免write skew。
思路
当一个事务A commit的时,
- 遍历txn_map_, 找到所有 状态为committed 且 在A.read_ts_之后commit的 事务 B。
- 遍历B的WriteSet,获得B修改过的table_oid 和 rid,进而读取此处tuple最新值。(个人认为此处不需要rollback)
- 遍历A的 scanPredicate,查看tuple是否能 fit in 这些 filer predicate。如果能,则说明有 SkewWrite,事务A Abort。
实现
1 | auto TransactionManager::CheckWriteSkew(Transaction *checked_txn, Transaction *conflict_txn) -> bool { |
即可通过 SerializableTest 测试。此时,Bustub可满足两种 Isolation level: Snapshot 和 Serializable。可以看出,现在Serializable verify 的开销还是很重的,需要把多个事务已经写入的tuple全部再读一遍。
结束
Bustub常规部分完结!(只剩下leaderboard部分)这玩意lab0-lab2都不算难,lab3、4才开始上强度。有的人呢觉得lab3最难,但我还是觉的lab4最难,多线程的bug卡了我好久吗,读写同步进行所以写入时要保持读取结构正确也是之前没写过没注意到的。只能说不要相信长夜将至,因为火把就在你的手里!

参考资料
https://blog.csdn.net/weixin_61432764/article/details/140965089
https://4ever-xxxl.github.io/cmu-15445-project-4/#foreword
https://blog.csdn.net/shuiyihang0981/article/details/143946393
https://zhuanlan.zhihu.com/p/679864449
https://zhuanlan.zhihu.com/p/687529756
https://blog.csdn.net/weixin_61432764/article/details/140965089