CS144 Lab1 Stitching substrings into a byte stream
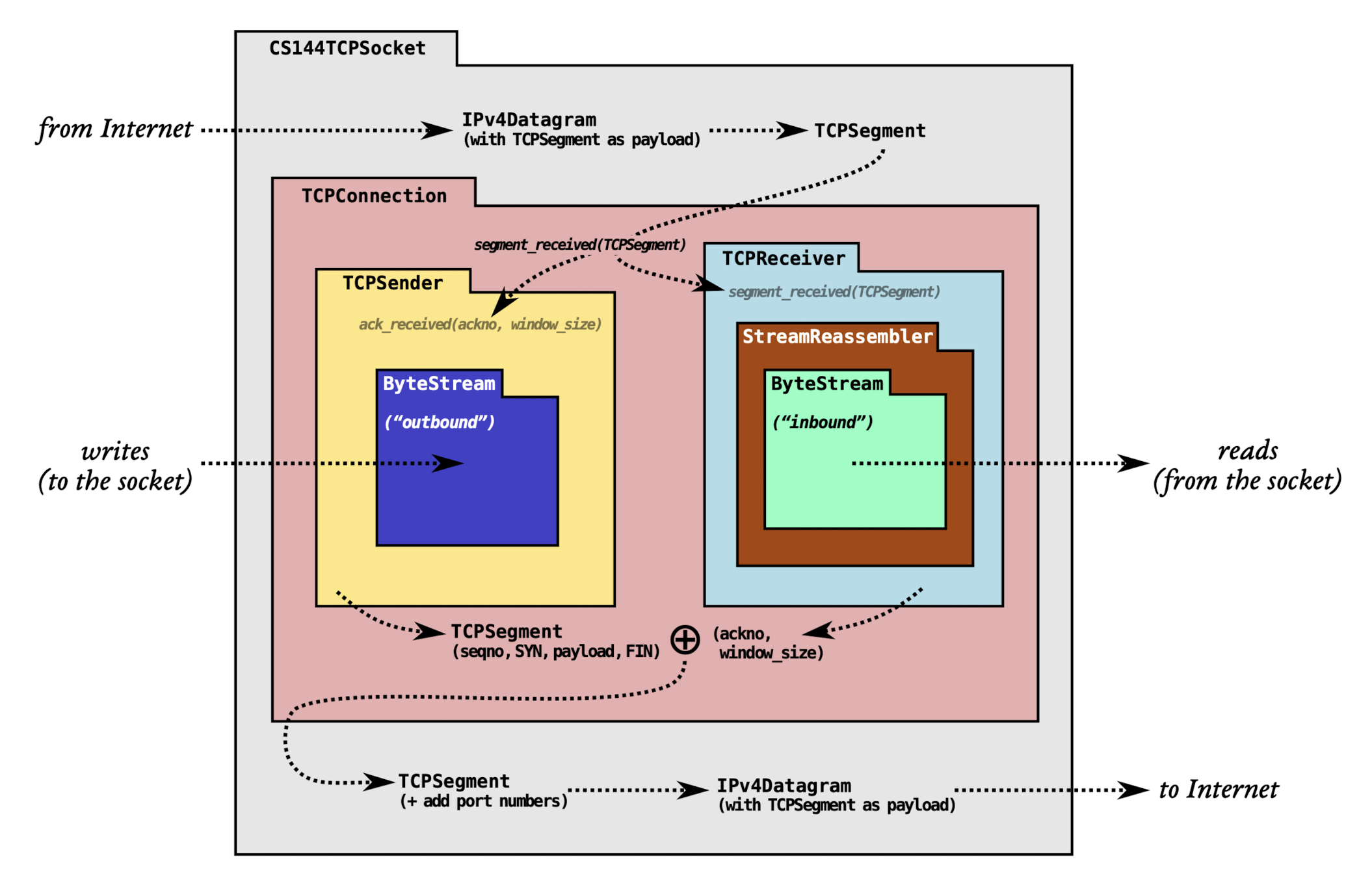
Lab0 体验了操作系统自带的socket的使用。接下来 Lab1 ~ Lab4 会逐步实现上图这样的一个CS144TCPSockert (socket不一定是基于TCP,也可以是UDP,所以这个叫TCPSocket),利用不可靠的Network层实现一个可靠的传输流。
Lab1实现的是StreamReassembler。如图,StreamReassembler是位于TCP接收端。从Network层接收过来的包非常杂乱,可能丢失、颠倒、重复、错误,而StreamReassembler的作用就是把这些乱七八糟的包重组成原本的模样。就像给一副混乱的扑克牌,让它给你重组成出厂的顺序。
思路
这个需要byte-wise存储。
但是,我刚开始想的:TCP sender端是按package重发的,因为sender是切割package内容不会重合,重发的时候也只会重发相同的内容,所以按道理来说发过来的package不会出现重合的情况,也就是StreamReassembler接收的substring不会出现重合的情况。但是直到写完了才发现测试中却有重合的情况,因为目前还没看其余部分,所以具体为啥会重合就不太清楚,但也只能改成按每个字节记录了。以上为刚写时的感言,后续发现,
之所以bytes-wise存储,是因为TCP中seqno也是byte-wise而不是segment-wise的。进一步的原因是TCP本质是字节流,不是“包”流。
根据这个博客的实测,如果用std::map的log(n)复杂度会超时。但这位大佬用的std::vector储存,我觉得如果assemble之后释放内存,std::vector内部会移动所有剩余字节,传来的bytes太不连续的话就会非常频繁地调用复制粘贴,效率会很低。但如果assemble完不释放,当这个class运行久了,就会占据非常大量的内存,设计个定期释放又太麻烦。
我又想到直接用std::unordered_map, 键为index,值为char。这样直接常数插入,还可以自动回收空间,但spatial locality太差。
我突然想到了我在写前面Lab0解析中介绍过的std::deque。这个底层大概是一个array,每个entry指向一个固定大小的block(有点类似文件系统里的inode),索引访问、pop_front() 时间复杂度都是O(1),且pop_front()后不会移动block内的数,而用一个指针表示,StreamReassembler只会从头pop的特性也让从中间插入不会发生,扩容时resize也比std::vector更快,而且也有很好的spatial locality,block size对齐cacheline,prefetch下个block,让连续pop_front也很快。
而capacity的定义可见下图:
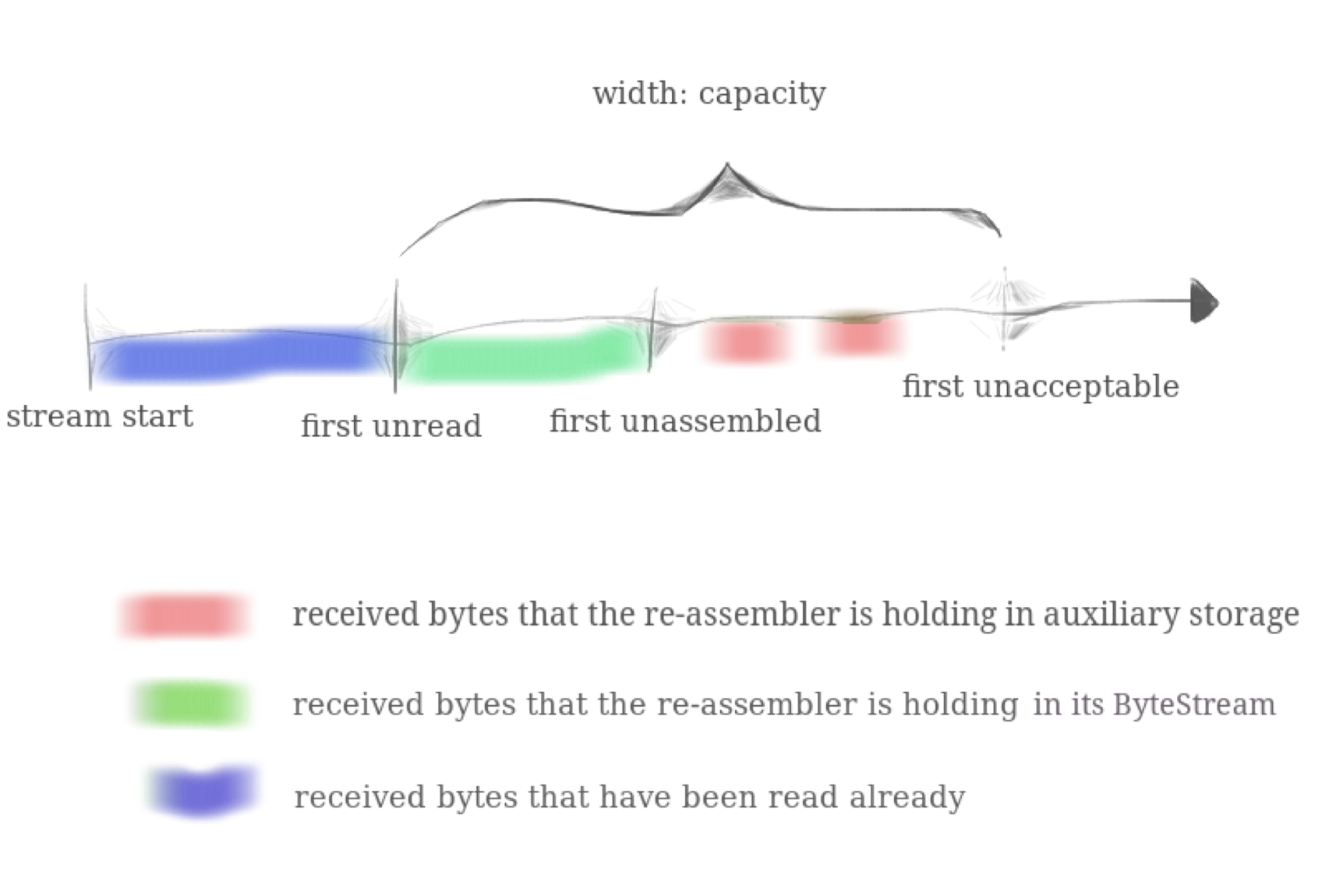
要注意unassembled中的“空格”也算在capacity其中。比如先加入“abc” index=0,再加入“ghX”,index = 6, 那么此时虽然“c”和“g“之间的char还不在,但也要算在capacity中(上图红色部分很清楚的表示这点)。所以这个例子中capacity=9。
代码
添加新成员,unassembled bytes放在std::deque里,assemble bytes放进ByteStream里。
1 | class StreamReassembler { |
stream_reassembler.cc中:
1 | void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) { |
结果
我一直用docker来做这个lab,但遇到了个很诡异的bug。在docker容器里测试lab1,会随机遇到测试卡住的情况,并且被卡住的test很随机。有时候零点几秒通过,但又有时候卡住动不了。我不用make check_lab1而直接运行单个test又不会遇到类似情况。我换到虚拟机后就不会随机卡住的情况,每一次都是顺利通过所有测试。遇到docker用不了的情况,具体不太清楚咋回事,先记录下来。
换到虚拟机里测试:
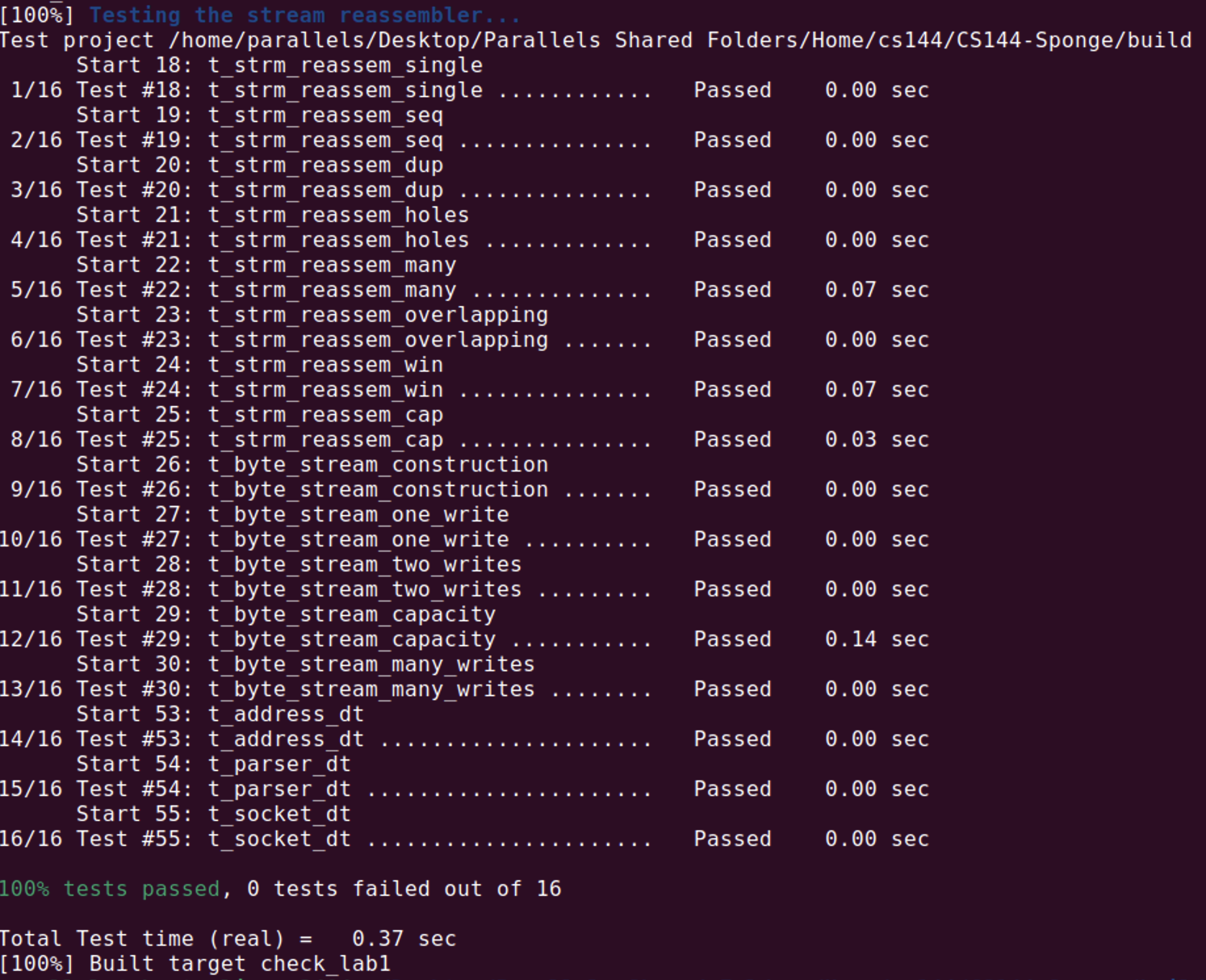
速度还是很快的,兼顾了空间和速度,std::deque还是很可靠。